A generalized reinforcement learning convolutional neural network
Cardbot
Cardbot in it's last iteration.
Bachelor Thesis
Non Destructive Reverse Engineering of PCBs
DIY 3D printed 4-bay NAS
A self designed and printed 4 bay NAS with a raspberry pi and software RAID.
The Pi Cap Fetch Machine
A sponsored project with capacitive touch realized with a robot.
Welcome to my humble website! Here you can find all bigger projects I did and had documented in the past that seemed interesting enough to put on here. I plan to not make this a frequent blog of mine, but rather a log of my projects.
Below are some of my most recent posts. Have fun poking around!
In this Godot Wild Jam #80 we had a team of 6 people. Two of which have never used the godot engine before, so it was a learning jam for them. This was a 9 day jam.
In this Weekend long game jam “PULS GAME JAM 2025“, we (a team of 3), have created a game in Unity. An engine that I have not used in a while and was kind of rusty. Nonetheless we have created a small cozy fishing game in which you are on a frozen lake that breaks over time.
Also we had time problems and two people could not participate in development for a day each.
While creating the concept of a new University module that has the students do a project with the Turtlebot3 robots and RL, a few ideas emerged. While evaluating different robot simulation tools for Reinforcement Learning, one in particular caught my eye: the Godot plugin “godot_rl_agents” by edbeeching. This was the result of a paper creating a bridge from Godot to RL libraries like StableBaselines3.
After trying the plugin it was clear that good result can be achieved quickly, there emerged the idea that students might be more encouraged learning the whole software stack when it involves a popular game engine instead of a “random” simulator with its own proprietary structure and configuration. So now it had to be proven that Sim2Real works with this Situation.
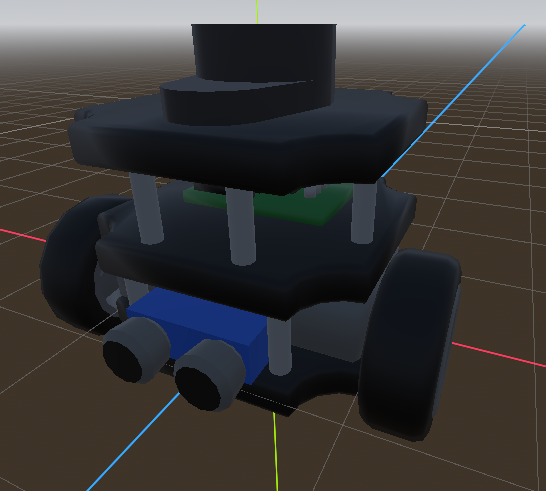
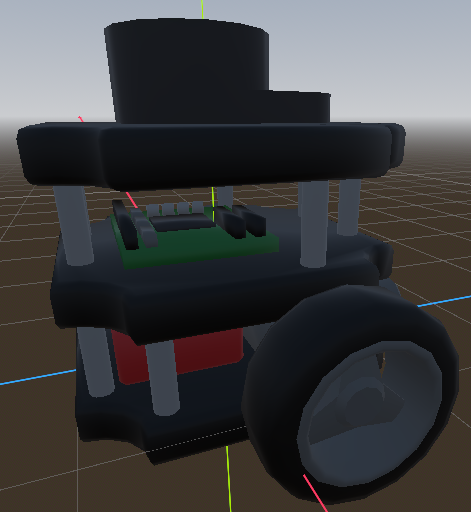
A friend modelled a “digital twin” of a turtlebot3, as the existing open source models usually used were very unoptimized and would hinder performance of actual training. It was purposefully minimal, but with accents to make it recognizable.
At first there was an example with just driving to a target point based on the map. No sensors needed. Simulation:
This was the first result:
The robot visible moves pretty badly in this clip. The reason which was later found: When the sent velocity commands would result in a jerky movement, the controller kind of rejects it and sometimes only does a part of the movement. Or sometimes no movement at all. To counteract this, the input has to be smoothed out beforehand to resist rejection from the controller.
Here is the next experiment with the lerp in mind:
This was the result:
The video shows that the robots performance can definitely be improved regarding stability and sensor calculations. Another big problem is also very visible here in that the small metal caster on the back of the turtlebot is very incompatible with the labs’ carpet flooring. This will be mitigated in the future with wooden plates that will make up the box’s floor.
In this 9 day long game jam, the team of three of us aimed to swap the main roles in the team. So the programmers were to create art, and the artist was supposed to code the game. We did not pull this through completely and had more of a mix towards the end. But we stepped out of our usual roles more than usual. We chose the “Godot Wild Jam #74” for this.
We did not explicitly use any of the possible “wild cards”.
This game is kind of a walking sim/narrative type.
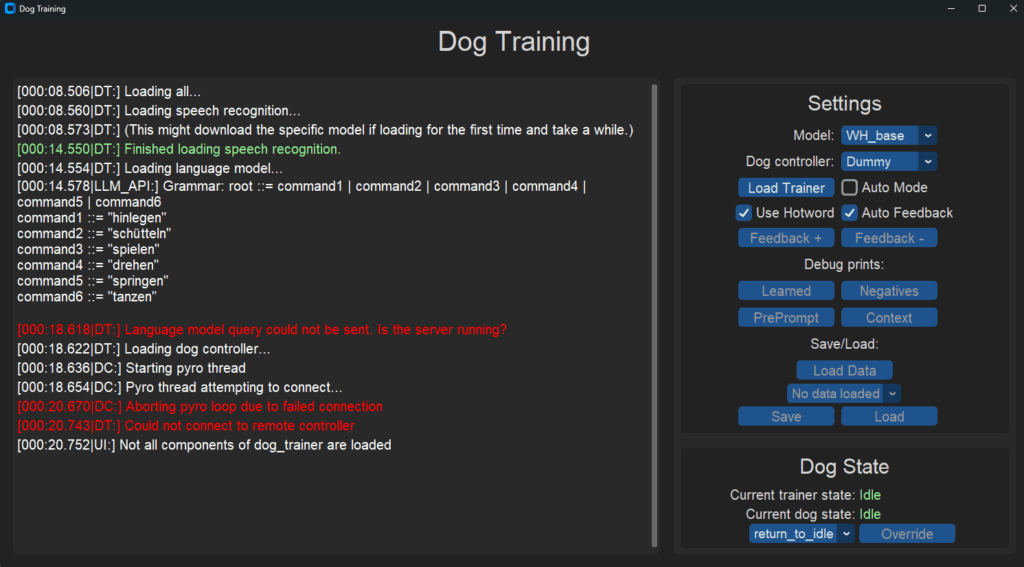
My master thesis topic was “Verbal training of a robot dog“. In this thesis I have created a program stack that tries to simulate real dog training. There are a few pre programmed actions the dog can perform, and it can either “anonymize” the actions or have a few preloaded commands for them. The usual training was done without any previous knowledge and from scratch.
A training step goes likes this: – (optional: Hotword recognition “Hey Techie!” to await actual speaking intent) – Speech recognition with “Whisper” (Open-source Speech-to-text from OpenAI) – Check if command has confirmed matches – Check if command has a small Levenshtein distance to a confirmed command (like “sit” and “sat”) – Query the local LLM which command could be used – If the LLM fails or picks a confirmed negative, a random action is rolled from the remaining actions – The dog executes the picked action – The dog awaits Feedback: Listens to “Yes” & “Correct” for positive, and “No” & “Wrong” for the negative feedback – The picked Command + Action Combo is memorized – The Loop repeats
The end result was a soft success. The training itself had to rely on quite a bit of randomness, since a very weak and small LLM was used which could’ve accelerated the process immensely. The same goes for the speech recognition, which failed a lot of times and resulted in bogus text recognized. With the stronger models it worked way better, but the calculation time was reduced from practically real time to up to 30 seconds, which was unacceptable in this case.