While creating the concept of a new University module that has the students do a project with the Turtlebot3 robots and RL, a few ideas emerged. While evaluating different robot simulation tools for Reinforcement Learning, one in particular caught my eye: the Godot plugin “godot_rl_agents” by edbeeching. This was the result of a paper creating a bridge from Godot to RL libraries like StableBaselines3.
After trying the plugin it was clear that good result can be achieved quickly, there emerged the idea that students might be more encouraged learning the whole software stack when it involves a popular game engine instead of a “random” simulator with its own proprietary structure and configuration. So now it had to be proven that Sim2Real works with this Situation.
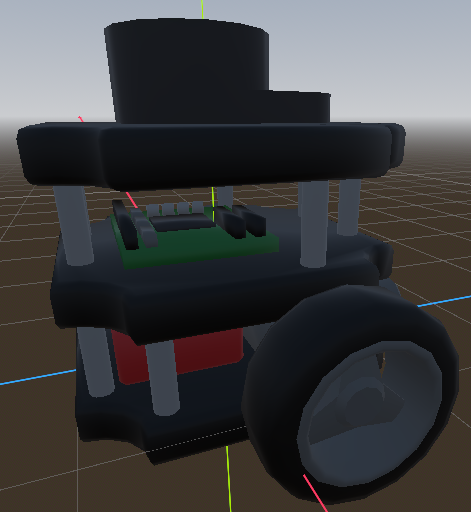
A friend modelled a “digital twin” of a turtlebot3, as the existing open source models usually used were very unoptimized and would hinder performance of actual training. It was purposefully minimal, but with accents to make it recognizable.
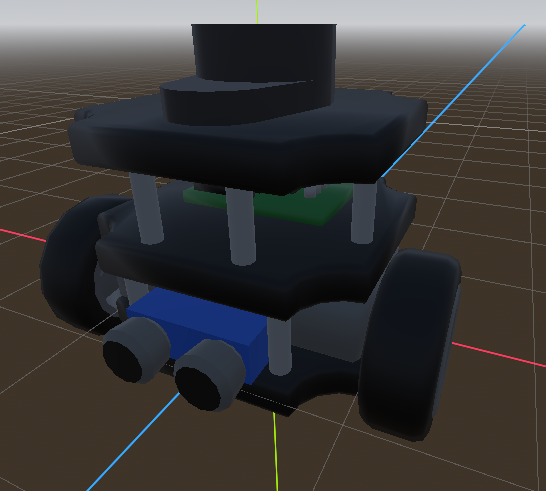
At first there was an example with just driving to a target point based on the map. No sensors needed.
Simulation:
This was the first result:
The robot visible moves pretty badly in this clip. The reason which was later found: When the sent velocity commands would result in a jerky movement, the controller kind of rejects it and sometimes only does a part of the movement. Or sometimes no movement at all. To counteract this, the input has to be smoothed out beforehand to resist rejection from the controller.
Here is the next experiment with the lerp in mind:
This was the result:
The video shows that the robots performance can definitely be improved regarding stability and sensor calculations. Another big problem is also very visible here in that the small metal caster on the back of the turtlebot is very incompatible with the labs’ carpet flooring. This will be mitigated in the future with wooden plates that will make up the box’s floor.